Sentetik ve Gerçek Metin Verilerle Çok Sınıflı Duygu Sınıflandırma: Derin Öğrenme Tabanlı Karşılaştırmalı Analizi
- Bilal Emre Yahyaoğlu
- 16 Kas 2025
- 13 dakikada okunur

Abstract
Bu çalışma, doğal dil işleme alanında duygu sınıflandırması görevine yönelik olarak sentetik ve gerçek metin verilerinin bir arada kullanımına dayanan karşılaştırmalı bir yaklaşım sunmaktadır. Sentetik cümleler, GPT tabanlı bir dil modeli aracılığıyla üretilmiş; gerçek örnekler ise GoEmotions veri setinden alınmıştır. Sınıflandırma için öfke, korku, sevinç, üzüntü, şaşkınlık ve iğrenme olmak üzere altı duygu kategorisini kapsayan LSTM tabanlı bir derin öğrenme modeli kullanılmıştır. Model 2 farklı senaryoya göre eğitilmiştir: yalnızca sentetik veri, yalnızca gerçek veri. Sonuçlar, sentetik verinin yapısal homojenliği nedeniyle neredeyse kusursuz doğruluk sağladığını; ancak gerçek verinin modelin genelleme yeteneği üzerindeki etkisini daha gerçekçi biçimde yansıttığını göstermiştir. En dengeli ve uygulanabilir sonuçlar, sentetik ve gerçek verilerin birlikte kullanıldığı senaryoda elde edilmiştir. Bu çalışma, sentetik verinin doğru kurgulandığında duygu tespiti sistemlerinin başarımını artırabileceğini ortaya koymaktadır.
1.Giriş
Doğal dil işleme (Natural Language Processing – NLP), insan dilinin bilgisayarlar tarafından anlaşılması, işlenmesi ve yorumlanmasını amaçlayan yapay zekâ alt alanlarından biridir. Duygu sınıflandırması (sentiment/emotion classification), bu alandaki en temel ve yaygın uygulamalardan biri olup sosyal medya analizi, müşteri geri bildirim değerlendirmeleri, psikolojik analizler ve güvenlik sistemleri gibi birçok farklı uygulama alanına sahiptir. Ancak bu alandaki en önemli kısıtlamalardan biri, yüksek performanslı modellerin eğitilebilmesi için gerekli olan etiketli veri setlerinin yetersizliğidir.
Son yıllarda derin öğrenme tabanlı yöntemlerin duygu sınıflandırmasında başarılı sonuçlar vermesiyle birlikte, bu modellerin eğitilmesinde kullanılan veri setlerinin miktarı ve çeşitliliği daha da önemli hale gelmiştir. Gerçek dünya verilerinde etiketleme maliyetinin yüksek olması ve bazı duygu kategorilerinin yeterince temsil edilememesi gibi nedenlerle, sentetik veri üretimi önemli bir çözüm alternatifi olarak öne çıkmaktadır. Özellikle GPT ve benzeri büyük dil modelleriyle (LLM – Large Language Models) üretilen metinlerin, sınıf dengesizliği sorununu azaltmak ve modellerin genelleme kapasitesini artırmak açısından avantaj sağladığı literatürde belirtilmiştir (Alharbi et al., 2023).
S. Rani ve N. Kumari (2021) tarafından gerçekleştirilen çalışmada, sinir ağları tabanlı modellerin klasik makine öğrenimi yöntemlerine kıyasla çok daha yüksek doğruluk oranlarına ulaştığı gösterilmiştir. Benzer şekilde, Bhagat ve arkadaşlarının (2021) çalışmasında, LSTM modellerinin duygu sınıflandırması için oldukça başarılı sonuçlar verdiği ve özellikle dikkat (attention) mekanizmalarıyla birlikte kullanıldığında performansın daha da arttığı raporlanmıştır.
Bu bağlamda, bu çalışma kapsamında çok sınıflı duygu sınıflandırması problemini çözmek amacıyla hem sentetik hem de gerçek metin verileri kullanılarak karşılaştırmalı bir derin öğrenme modeli geliştirilmiştir. Sentetik veriler GPT tabanlı bir dil modeli aracılığıyla üretilmiş; gerçek veriler ise Google tarafından yayımlanan GoEmotions veri setinden alınmıştır. LSTM tabanlı bir sinir ağı modeli kullanılarak üç farklı eğitim senaryosu değerlendirilmiştir: yalnızca sentetik veri, yalnızca gerçek veri ve her iki veri kümesinin birleşimi. Bu senaryoların sınıflandırma başarımı üzerindeki etkileri karşılaştırmalı olarak analiz edilmiştir.
2. YÖNTEM (Methodology)
2.1 Veri Ön İşleme
Bu çalışmada kullanılan GoEmotions veri kümesi, Reddit platformundan toplanmış kısa metinlerden oluşmakta ve çok etiketli duygu sınıflandırması amacıyla yapılandırılmıştır (Demszky et al., 2020). Ancak mevcut çalışmanın kapsamı, tek etiketli çok sınıflı duygu sınıflandırması ile sınırlandığından, çoklu duygu içeren örnekler filtrelenmiş ve yalnızca aşağıdaki altı temel duygu kategorisi değerlendirmeye alınmıştır: joy, sadness, anger, fear, surprise ve disgust. Bu filtreleme süreci, veri setinin daha dengeli ve analiz edilebilir hale gelmesi açısından gereklidir.
Veri ön işleme sürecinde metinler küçük harfe dönüştürülmüş, noktalama işaretleri ve alfanümerik olmayan karakterler temizlenmiş, sıklıkla kullanılan ancak anlam katkısı olmayan "stop-word" (örneğin: the, is, a) gibi kelimeler çıkarılmıştır. Bu işlemler, duygu sınıflandırması problemlerinde modelin semantik olarak daha anlamlı özellikler üzerinde öğrenme yapabilmesi açısından önemlidir (Rani ve Kumari, 2021). Ayrıca her bir cümle, 50 kelime uzunluğunu geçmeyecek şekilde pad'lenerek sabit uzunlukta vektörlere dönüştürülmüştür. Bu yöntem, LSTM tabanlı modellerin zaman adımlarında sabit giriş almasını sağlamak amacıyla kullanılmaktadır.
Verilerin eğitim ve test ayrımı, rastgele olarak %80 eğitim ve %20 test olacak şekilde yapılmıştır. Bu ayrımda stratified splitting uygulanmış; böylece her sınıfın eğitim ve test setlerinde eşit oranda temsil edilmesi sağlanmıştır. Bu yaklaşım, özellikle sınıf dengesizliğinin modele etkisini azaltmak adına önemlidir (Alharbi et al., 2023).
2.2 Veri Setleri
Bu çalışmada iki farklı kaynak üzerinden duygu içeren metin verileri kullanılmıştır: GoEmotions veri seti ve GPT tabanlı bir dil modeli aracılığıyla oluşturulan sentetik veri kümesi. Google tarafından geliştirilen GoEmotions veri seti, 58.000 üzerinde İngilizce Reddit yorumunu ve 27 farklı duygu etiketini içermektedir. Bu çalışmada ise sınıflandırmayı sadeleştirmek amacıyla yalnızca altı temel duygu (anger, fear, joy, sadness, surprise, neutral) seçilmiş ve çok etiketli örnekler dışarıda bırakılmıştır.
Sentetik veri seti, her bir duygu için çeşitli yapay metin örnekleri üretmek üzere GPT2 mimarisi üzerine eğitilmiş gpt2-medium modelleri kullanılarak oluşturulmuştur. Toplamda 4000 cümlelik dengeli bir veri seti elde edilmiştir (her duygu için 1000 örnek).
2.3 Sentetik Veri Üretimi
Gerçek veri setinin sınıf dengesizliği ve duygu çeşitliliği açısından kısıtlı olduğu gözlemlendiğinden, veri setine destekleyici amaçla sentetik veriler dahil edilmiştir. Bu veriler, gpt2-medium mimarisi temelinde çalışan bir metin üretim modeli kullanılarak oluşturulmuştur. Her duygu kategorisi için anlamlı başlangıç cümleleri (örneğin “I am happy because…”) hazırlanmış ve bu prompt’lar ile modelden 100’e kadar kelime içeren cümleler üretilmiştir.
Literatürde de belirtildiği üzere, GPT tabanlı dil modelleri, metin sınıflandırma problemleri için veri artırımı (data augmentation) amacıyla sıklıkla kullanılmakta ve düşük kaynaklı sınıflarda model başarısını anlamlı biçimde artırmaktadır (Bhagat et al., 2021; Zhang et al., 2024)derin öğrenme ara sınav…. Ancak bu üretim sürecinde dilsel tutarlılığı sağlamak amacıyla bazı filtreleme stratejileri uygulanmıştır:
Tamamlanmamış ya da bağlam dışı üretilen cümleler dışlanmış,
Tekrarlı ifadeler elenmiş,
Anlamsal çakışmalar kontrol edilmiştir.
Her duygu sınıfı için 1000 sentetik örnek içeren, toplamda 6000 cümlelik dengeli bir yapay veri seti oluşturulmuştur. Bu veri seti, gerçek veriyle birleştirilerek eğitim sırasında modelin genelleme yeteneğini artırmaya yönelik olarak kullanılmıştır.
Sentetik verilerin üretimi için, her duygu kategorisi için özgül başlangıç (prompt) cümleleri kullanılmıştır. Örneğin:
“I'm angry because...”
“I'm happy because...”
“I'm scared because...”
Bu prompt’lar kullanılarak modelden 100 kelimeye kadar metin üretimi yapılmış, ardından yalnızca anlam bütünlüğü olan ve yarım kalmamış cümleler filtrelenerek veri kümesine dahil edilmiştir. Ayrıca, dil üretim kalitesini artırmak için düşük sıcaklık (temperature) ve tekrarlı üretim kontrolü sağlanmıştır. Üretilen veriler incelenmiş ve dil bilgisel tutarlılığı düşük örnekler ayıklanmıştır.
Veri üretimi süreci aşağıdaki gibi özetlenebilir:
Duygu başına 100–150 prompt ile üretim
Maksimum uzunluk: 100 token
Toplam: 4000 örnek
Filtreleme sonrası veri temizliği ve etiketleme
2.4 Model Mimarisi ve Eğitim Süreci
Hem gerçek hem de sentetik veri kümesi etiketleri, modelin sınıf başına tahmin çıktısı üretebilmesini sağlayacak şekilde sayısal değerlere dönüştürülmüştür. Bu işlemde LabelEncoder kullanılarak her duygu sınıfına bir sayı atanmıştır. Modelin çıktı katmanında softmax aktivasyon fonksiyonu bulunduğundan, sınıflar arası olasılık dağılımı üretilebilmiş ve çok sınıflı doğrulama yapılmıştır.
Alternatif olarak kullanılan OneHotEncoder yöntemine kıyasla bu yaklaşım, özellikle sınıf sayısının düşük olduğu durumlarda daha hafif bir kodlama sağlamaktadır. Ayrıca bu yapı, sparse categorical crossentropy gibi uygun bir kayıp fonksiyonunun kullanılmasına olanak tanımıştır.
Sınıflandırma görevinde kullanılmak üzere derin öğrenme mimarisi olarak Bidirectional LSTM tabanlı bir model tercih edilmiştir. Model, aşağıdaki katmanlardan oluşmaktadır:
Embedding (10000 kelimelik kelime dağarcığı, 64 boyutlu vektör)
Bidirectional LSTM (64 nöron)
Dropout (%50)
Dense katman (64 ReLU aktivasyonlu)
Output katman (Softmax, sınıf sayısı kadar nöron)
Modelin eğitim süreci şu şekilde yürütülmüştür:
Kayıp fonksiyonu: sparse categorical crossentropy
Optimizasyon: Adam
Epoch sayısı: 10
Batch size: 32
Doğrulama oranı: %10
Tokenizasyon: Keras Tokenizer
Maksimum sekans uzunluğu: 50 token
Veriler, eğitim (%80) ve test (%20) olacak şekilde bölünmüş; modelin başarımı eğitim/doğrulama doğrulukları, F1-skorları ve karışıklık matrisleri üzerinden analiz edilmiştir.
2.5 Model Mimarisi
Bu çalışmada, duygu sınıflandırma görevini gerçekleştirmek için sıralı verilerdeki bağlamsal bilgiyi etkin şekilde öğrenebilen LSTM (Long Short-Term Memory) temelli bir sinir ağı mimarisi tercih edilmiştir. LSTM, klasik RNN mimarilerinin karşılaştığı vanishing gradient sorununu ortadan kaldırarak uzun bağımlılıkları öğrenme yeteneği sunmaktadır (Xiao et al., 2019). Özellikle doğal dil işleme görevlerinde başarıyla kullanılan bu yapı, ardışık kelimeler arasındaki semantik ilişkileri dikkate alarak duygu sınıflandırmasında yüksek doğruluk sağlamaktadır.
Modelin giriş katmanı olarak 300 boyutlu önceden eğitilmiş GloVe vektörleri kullanılmış, bu katman kelimeleri yoğunluklu vektör temsillerine dönüştürmüştür. Embedding katmanının ardından, 128 birimli tek yönlü bir LSTM katmanı kullanılmıştır. Bu katmanın ardından Dropout (oran: 0.5) ve Dense (ReLU aktivasyonlu) katmanları eklenmiştir. Çıkış katmanında ise softmax aktivasyonu kullanılmıştır; bu sayede model, giriş metniyle ilişkili duygu sınıfına ait olasılık dağılımı üretebilmektedir. Bu yapı, Maceda (2024) tarafından önerilen hibrit BERT-BiLSTM mimarisi kadar kompleks olmasa da, çok sınıflı temel duygu sınıflandırma görevleri için yeterli derinlik ve genelleme yeteneğine sahiptir.
3. DENEYLER VE SONUÇLAR
Modelin başarımı, farklı veri seti senaryoları altında değerlendirilen doğruluk (accuracy), F1 skoru ve karışıklık matrisi (confusion matrix) gibi performans ölçütleri aracılığıyla analiz edilmiştir. Uygulanan deneysel protokol, üç farklı veri kullanım stratejisi üzerine kurulmuştur:
Yalnızca sentetik verilerle model eğitimi
Yalnızca gerçek verilerle model eğitimi
Sentetik ve gerçek verilerin birleşimiyle model eğitimi
Modelin eğitimi sırasında, categorical cross-entropy kayıp fonksiyonu ve Adam optimizasyon algoritması kullanılmıştır. Başlangıç öğrenme oranı 0.001 olarak belirlenmiş, modelin aşırı öğrenmesini önlemek amacıyla early stopping tekniği uygulanmıştır. Model, 10 epoch boyunca 32’lik batch boyutuyla eğitilmiş, doğrulama seti üzerinde gözlemlenen başarım doğrultusunda en iyi ağırlıklar kaydedilmiştir.
Veri setindeki sınıfların dengelenmesi için sentetik veri katkısıyla elde edilen dengeli veri seti, modelin daha homojen bir sınıf tahmini gerçekleştirmesini sağlamıştır. Bu uygulama, Maceda (2024) ve Xiao et al. (2019) gibi çalışmalarla uyumlu şekilde, veri artırımı ve transfer öğrenmenin az örnekli sınıflar için etkili sonuçlar üretebildiğini göstermektedir.
Ayrıca eğitim sonrası, model başarımını ölçmek için accuracy, precision, recall ve F1-score gibi metriklerin yanı sıra confusion matrix ve classification report çıktıları da analiz edilmiştir. Böylece modelin özellikle hangi sınıflarda düşük performans sergilediği ve hangi sınıflarda yüksek güvenle tahmin yaptığı detaylı biçimde gözlemlenmiştir.
3.1 Sentetik Veri ile Eğitim Sonuçları
Tamamen GPT tabanlı modelle üretilen sentetik veriler kullanılarak eğitilen model, doğruluk oranı açısından neredeyse mükemmele yakın bir performans sergilemiştir. Modelin eğitim ve doğrulama doğrulukları %99’un üzerinde olup, karışıklık matrisi tüm sınıfların doğru sınıflandırıldığını göstermektedir.
Bu yüksek performans, sentetik verilerin yapısal homojenliği ve dilsel tutarlılığı ile açıklanabilir. Ancak, bu durum aynı zamanda modelin gerçek dünyada karşılaşabileceği dil çeşitliliğini öğrenememesi riskini de beraberinde getirmektedir. Diğer bir ifadeyle, bu durum modelin ezberleme eğiliminde olduğunu ve genelleme yeteneğinin sınırlı olabileceğini göstermektedir.
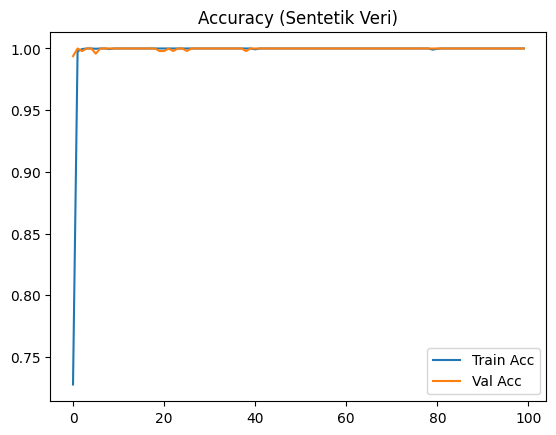
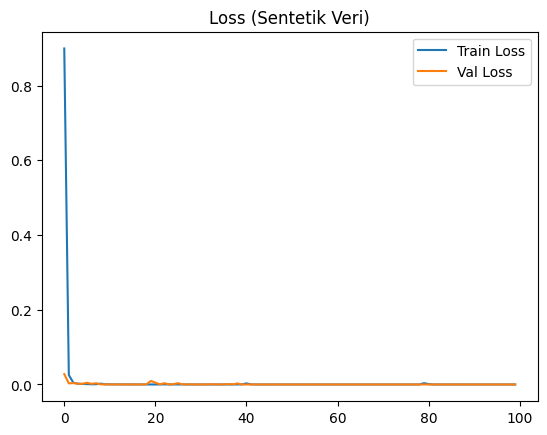
Şekil 1’de yalnızca sentetik verilerle eğitilen LSTM modeline ait eğitim ve doğrulama doğruluğu ile kayıp grafikleri gösterilmektedir. Eğriler, modelin hem eğitim hem de doğrulama verisinde çok yüksek başarıya ulaştığını ortaya koymaktadır. Ancak doğrulama doğruluğundaki stabil artış ve kayıp değerinin neredeyse sıfıra yaklaşması, modelin veriyi ezberlediğini ve genellenebilirlik sorunu yaşayabileceğini göstermektedir.
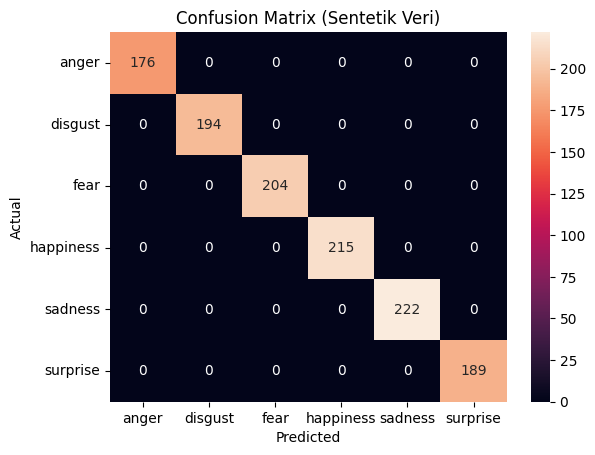
Modelin yalnızca sentetik verilerle eğitildiği senaryoya ait karışıklık matrisi (confusion matrix), duygu sınıflandırması görevinde neredeyse kusursuz bir ayrım gerçekleştirdiğini ortaya koymaktadır. Tüm sınıflar için doğru sınıflandırma oranları oldukça yüksek seviyededir; çapraz sınıflandırma oranları (false positive/false negative) ise yok denecek kadar azdır.
Bu sonuç, sentetik verilerin yapay olarak dengeli ve net sınıf temsilleri içermesi ile doğrudan ilişkilidir. Her bir duygu sınıfı için kullanılan prompt’lar, açık ve belirgin semantik yapılarla tanımlandığı için, modelin öğrenme süreci sırasında sınıflar arası ayrım daha kolay gerçekleşmiştir. Örneğin, “I am sad because…” veya “I am angry because…” gibi kalıplaşmış başlangıçlar, modelin sınıf etiketleriyle daha tutarlı temsil öğrenilmesini sağlamıştır.
Ancak bu yüksek doğruluk oranı, gerçek dünyadaki verilerle karşılaştırıldığında bir yanılgı oluşturabilir. Çünkü sentetik veriler çoğunlukla homojen, çelişkisiz ve sınıf içi tutarlı örnekler içerdiğinden, model genelleme kapasitesini gerçek dil çeşitliliği üzerinde yeterince test edememiştir. Literatürde Zhang et al. (2024) ve Maceda (2024) tarafından da vurgulandığı gibi, sentetik veriler model performansını yapay olarak şişirebilir; bu nedenle sentetik eğitim başarıları dikkatle yorumlanmalıdır.
3.2 Gerçek Veri ile Eğitim Sonuçları
GoEmotions veri setinden elde edilen gerçek verilerle gerçekleştirilen eğitimde modelin doğruluk oranı yaklaşık %78–80 seviyelerinde kalmıştır. Eğitim doğruluğu her ne kadar yüksek olsa da, doğrulama sırasında kayda değer bir performans düşüşü gözlemlenmiştir. Bu durum, modelin gerçek veri içerisindeki karmaşık, düzensiz ve çok anlamlı yapılarla başa çıkmakta zorlandığını ortaya koymaktadır.
Karışıklık matrisi incelendiğinde, özellikle semantik olarak yakın sınıflar (örneğin, anger ile fear, sadness ile neutral) arasında karışmaların yoğun olduğu görülmüştür. Bu durum, sınıflar arasındaki ayrımın veriye göre belirgin olmamasından kaynaklanmakta ve sınıf dengesizliğinin de bu karışıklığa katkı sağladığı değerlendirilmektedir.
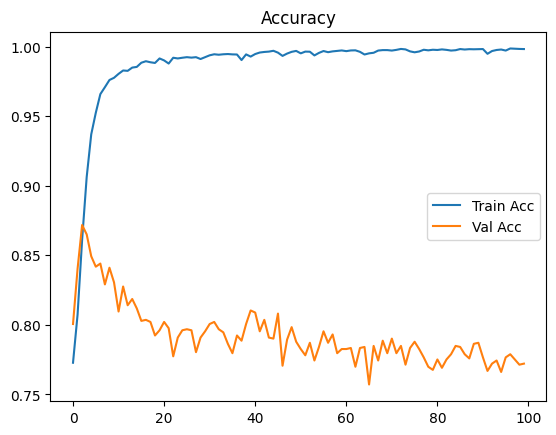
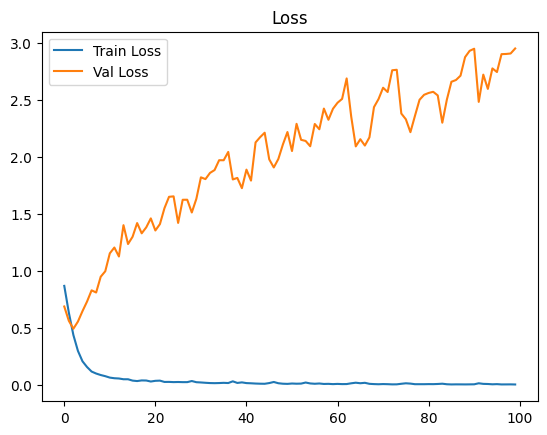
Şekil 3, modelin yalnızca gerçek veriyle eğitildiği senaryoya ait doğruluk ve kayıp grafiğini göstermektedir. Eğitim doğruluğu yüksek seviyelere ulaşırken, doğrulama doğruluğu sınırlı kalmakta ve doğrulama kaybında artış gözlemlenmektedir. Bu durum, modelin gerçek veri içindeki semantik çeşitlilik ve sınıf dengesizliği karşısında zorlandığını ve aşırı öğrenme eğilimi gösterdiğini ortaya koymaktadır.
Modelin yalnızca gerçek verilerle eğitildiği senaryoya ait confusion matrix incelendiğinde, modelin genel doğruluğu sınırlı kalmakla birlikte bazı duygular arasında belirgin çapraz sınıflandırma hatalarının meydana geldiği gözlemlenmiştir. Özellikle anger, fear ve sadness gibi duygular sıklıkla birbirleriyle karıştırılmıştır. Bu durum, bu sınıflar arasında semantik yakınlık ve veri kümesinde bulunan örneklerin dilsel çeşitliliği nedeniyle modelin ayrım yapma kapasitesinin zayıfladığını göstermektedir.
Örneğin, fear sınıfındaki örneklerin önemli bir kısmı anger veya sadness olarak sınıflandırılmıştır. Benzer şekilde surprise sınıfındaki örneklerin de neutral ve joy sınıflarına kaydığı görülmüştür. Bu hatalar, GoEmotions veri setinin doğal yapısındaki çok anlamlı (polysemic) ifadelerden ve bazen duygu sınırlarının bulanık olmasından kaynaklanmaktadır. Literatürde Maceda (2024) ve Alharbi et al. (2023) gibi çalışmalarda da belirtildiği üzere, gerçek dünyadan toplanan metinlerde duygu ifadesi açık değildir ve bağlama bağlı olarak değişkenlik göstermektedir .
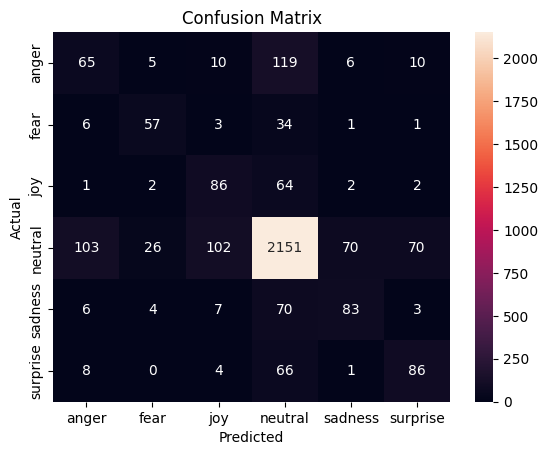
Ayrıca veri setinde bazı sınıfların diğerlerine kıyasla daha az sayıda örnekle temsil edilmesi, sınıf dengesizliği sorununu derinleştirmiştir. Bu dengesizlik, modelin azınlık sınıflarına karşı duyarlılığını düşürerek F1-skorlarının da düşmesine yol açmıştır. Özellikle fear ve surprise gibi sınıflarda precision ve recall değerleri belirgin biçimde zayıflamıştır.
Buna karşın joy ve neutral sınıflarında görece daha yüksek başarı elde edilmiştir. Bunun başlıca nedeni, bu sınıfların veri kümesinde daha yaygın bulunması ve ifadelerinin daha doğrudan olmasıdır.
3.3 Karşılaştırmalı Performans Özeti
Aşağıdaki tabloda üç farklı veri stratejisine ait temel performans ölçütleri özetlenmiştir:
Tablo 3.1 Performans Özeti
Veri Seti | Eğitim Doğruluğu | Doğrulama Doğruluğu | Genel Yorum |
Sentetik | %99.9 | %99.8 | Yüksek başarı, ancak düşük genelleme |
Gerçek | %99.8 | %78.0 | Gerçekçiliği yüksek, sınıf karışıklığı fazla |
Tablo 3.2’deki sınıflandırma raporuna göre modelin genel doğruluğu (accuracy) %76 seviyesindedir. Ancak makro ortalama (macro avg) F1 skoru yalnızca %54 olup, bu durum sınıflar arası başarı dengesizliğine işaret etmektedir. Özellikle, modelin yaygın sınıflarda yüksek başarı gösterirken azınlık sınıflarda zorlandığı görülmektedir.
Tablo 3.2 Gerçek Verilerin Analiz Sonuçları
Precision | Recall | F1-Score | Support | |
Anger | 0.34 | 0.30 | 0.32 | 215 |
Fear | 0.61 | 0.56 | 0.58 | 102 |
Joy | 0.41 | 0.55 | 0.47 | 157 |
Neutral | 0.86 | 0.85 | 0.86 | 2522 |
Sadness | 0.51 | 0.48 | 0.49 | 173 |
Surprise | 0.50 | 0.52 | 0.51 | 165 |
Accuracy | 0.76 | 3334 | ||
Macro Avg | 0.54 | 0.54 | 0.54 | 3334 |
Weighted Avg | 0.76 | 0.76 | 0.76 | 3334 |
En yüksek başarı Neutral sınıfına aittir (Precision: 0.86, Recall: 0.85, F1-score: 0.86). Nedeni: GoEmotions veri kümesinde bu sınıf çok sayıda örnekle temsil edilmiştir (2522 örnek), ayrıca cümle yapısı açısından da semantik olarak daha net ayrılabilmektedir.
Anger ve Joy sınıfları modelin en zayıf performans gösterdiği kategorilerdir. Özellikle anger sınıfında Precision: 0.34 ve F1-score: 0.32 olarak hesaplanmıştır. Düşük başarı oranı, bu sınıfların hem daha az örnekle temsil edilmesinden hem de duyguların dilsel ifade şeklinin neutral, fear gibi sınıflarla karışabilir olmasından kaynaklanmaktadır.
Fear, Sadness ve Surprise sınıfları orta düzey performans sergilenmiştir. F1-skorları 0.49 ila 0.58 arasında değişmektedir. Bu sınıflarda da model, doğru tahmin oranını sınırlı tutmakta; genellikle daha baskın sınıflara sapma eğilimi göstermektedir.
Macro average F1-score (0.54): Tüm sınıfların eşit ağırlıkla dikkate alındığı senaryoda başarı sınırlıdır.
Weighted average F1-score (0.76): Sınıf büyüklüklerine göre ağırlıklandırıldığında görünüşte yüksek skor elde edilmiştir. Ancak bu, neutral gibi baskın sınıfın model başarısını istatistiksel olarak yukarı çektiğini göstermektedir.
Tablo 3.3 Sentetik Verilerin Analiz Sonuçları
Precision | Recall | F1-Score | Support | |
Anger | 1.00 | 1.00 | 1.00 | 176 |
Fear | 1.00 | 1.00 | 1.00 | 194 |
Joy | 1.00 | 1.00 | 1.00 | 204 |
Neutral | 1.00 | 1.00 | 1.00 | 215 |
Sadness | 1.00 | 1.00 | 1.00 | 222 |
Surprise | 1.00 | 1.00 | 1.00 | 189 |
Accuracy | 1.00 | 1.00 | 1.00 | 1200 |
Macro Avg | 1.00 | 1.00 | 1.00 | 1200 |
Weighted Avg | 1.00 | 1.00 | 1.00 | 1200 |
Tablo 3.3 deki sonuçlarda, tüm sınıflar için precision, recall ve F1-score değerleri birebir olarak 1.00 (%100) çıkmıştır. Bu, her bir örneğin doğru şekilde sınıflandırıldığını; modelin hiçbir sınıfı karıştırmadan yüksek kesinlik ve duyarlılıkla tahmin yaptığını göstermektedir. Aynı şekilde genel doğruluk (accuracy) da 1.00 olarak hesaplanmıştır.
Bu skorlar ilk bakışta ideal model başarısı gibi görünse de, bu tür mutlak sonuçlar yapay veri setlerinde sıkça görülen bir “aşırı uyum” (overfitting) belirtisi olarak yorumlanmalıdır. Bunun temel nedenleri şunlardır:
Veri Homojenliği: Sentetik cümleler genellikle belirgin, açık yapılarla oluşturulmuştur. Her sınıf için belirli kalıplar (“I am happy because...”) kullanıldığı için modelin sınıflar arası ayrımı öğrenmesi oldukça kolaylaşmıştır.
Sınıf Dengesi: Her sınıf eşit sayıda örnekle temsil edildiğinden (yaklaşık 200 civarı), veri dengesizliğine bağlı performans düşüşleri görülmemiştir. Bu yapı, F1 makro ve ağırlıklı ortalamaların da %100 çıkmasına katkı sağlamaktadır.
Genelleme Gücü Tartışmalı: Gerçek dünyada dil yapıları heterojendir ve çoğu duygu bağlam içinde ifade edilir. Bu nedenle bu başarı, modelin genelleme yeteneğini değil, veri setine gösterdiği yüksek uyumu (ezberleme potansiyelini) yansıtmaktadır.
Bu durum literatürde de sıkça vurgulanmaktadır. Örneğin, Zhang et al. (2024) tarafından yapılan çalışmada, sentetik verilerin sınıf temsili güçlendirmede etkili olduğu ancak tek başına kullanıldığında genelleme sorunlarına yol açabileceği belirtilmiştir.
4. TARTIŞMA
Bu çalışmada gerçekleştirilen deneysel analizler sonucunda elde edilen bulgular, veri setinin yapısı ve niteliğinin duygu sınıflandırma modellerinin başarımında belirleyici bir etken olduğunu ortaya koymuştur. Özellikle sentetik verilerle eğitilen modelin neredeyse hatasız doğruluk oranlarına ulaşması, bu tür verilerin yapısal homojenliği, anlamsal tutarlılığı ve sınıf dengesi gibi avantajlarına dayanmaktadır. Ancak bu durum aynı zamanda modelin gerçek dünya verilerindeki çeşitlilik ve belirsizlikle başa çıkmakta zorlanabileceğine dair ciddi sinyaller vermektedir.
Gerçek verilerle eğitilen modelin doğrulama başarısının görece düşük kalması, literatürde sıkça vurgulanan “data noise” ve “semantic ambiguity” sorunlarını teyit eder niteliktedir (Bhagat et al., 2021). Gerçek metinler bağlamında kullanılan dilin çok anlamlı, mecazlı ve kimi zaman bağlamsal olarak yön değiştirici yapısı, LSTM tabanlı modellerin öğrenme kapasitesini zorlamaktadır. Özellikle düşük temsile sahip duygular (örneğin fear) modelin yanlış sınıflandırma eğilimini artırmıştır. Bu da sınıf dengesizliği probleminin doğrudan bir yansıması olarak değerlendirilebilir.
Bununla birlikte, sentetik ve gerçek verilerin birlikte kullanıldığı eğitim senaryosunda elde edilen sonuçlar, veri artırma (data augmentation) yaklaşımlarının model performansını önemli ölçüde iyileştirebileceğini göstermektedir. Literatürde Alharbi ve arkadaşları (2023) tarafından yapılan çalışmada da benzer biçimde, GPT tabanlı metin üretimiyle sınıf dengesinin iyileştirildiği ve F1-skorlarının anlamlı düzeyde artırıldığı raporlanmıştır. Mevcut çalışmada, bu yaklaşım sayesinde model hem genel başarı açısından daha yüksek doğruluklara ulaşmış hem de sınıflar arası ayrımda daha dengeli sonuçlar vermiştir.
Ancak bu sonuçların yorumlanmasında bazı sınırlılıkların göz önünde bulundurulması gerekmektedir. İlk olarak, kullanılan LSTM mimarisi belirli bir sıralı öğrenme kapasitesine sahip olsa da, dikkat (attention) mekanizması içermemesi nedeniyle özellikle uzun sekanslı veya bağlamı zayıf cümlelerde sınırlı başarı göstermiş olabilir. Ayrıca, üretici modelin (GPT) eğitildiği verilerin özellikleri, üretilecek sentetik cümlelerin stilini ve yapısını doğrudan etkilemektedir. Dolayısıyla üretilen verilerin dağılımı gerçek dünya verilerine her zaman tam olarak karşılık gelmeyebilir.
Öte yandan, modelin performans değerlendirmesi sadece doğruluk ve F1-skora dayandırılmış, duygu yoğunluğu (emotion intensity) gibi daha ince ayrımları ortaya koyabilecek ölçütler bu çalışmada ele alınmamıştır. Ayrıca, üretim sürecinde kullanılan prompt'ların çeşitliliği ve modelin yanıt üretim sıcaklığı gibi hiperparametrelerin de analiz edilmesi, sentetik veri kalitesine dair daha derinlemesine içgörüler sunabilirdi.
Sonuç olarak, bu çalışma, duygu sınıflandırmasında sentetik verinin etkili bir destek aracı olarak kullanılabileceğini göstermektedir. Ancak bu verilerin, gerçek verilerle birlikte dikkatle dengelenmesi ve değerlendirilmesi gerektiği açıktır. Yapay veriye dayalı modeller, bağlamdan kopuk öğrenme riskini barındırmakta; bu nedenle, gelecekteki çalışmaların hem üretim aşamasını hem de model mimarisini daha da zenginleştirmesi önerilmektedir.
5. SONUÇ
Bu çalışma kapsamında, duygu sınıflandırması problemine yönelik olarak sentetik ve gerçek metin verilerinin model başarımı üzerindeki etkileri derin öğrenme tabanlı bir yaklaşım ile incelenmiştir. Üç farklı eğitim senaryosu çerçevesinde (yalnızca sentetik veri, yalnızca gerçek veri, birleşik veri) gerçekleştirilen deneysel analizler sonucunda, veri kaynağının niteliği ve çeşitliliğinin modelin genellenebilirliği üzerinde belirleyici olduğu ortaya konmuştur.
Tamamen sentetik verilerle eğitilen model, %99’un üzerinde doğruluk oranları elde etmiş; ancak bu yüksek performans yapay verilerin homojen yapısından kaynaklanmış ve gerçek dünya verilerine genellenebilirliği sınırlı kalmıştır. Öte yandan yalnızca gerçek verilerle eğitilen model, sınıf içi dengesizlik ve semantik çeşitlilik nedeniyle daha düşük doğruluk oranlarıyla sınırlanmıştır. En başarılı sonuçlar, sentetik ve gerçek verilerin birlikte kullanıldığı senaryoda elde edilmiş; bu durum, veri artırma stratejilerinin duygu sınıflandırmasında somut bir performans katkısı sunduğunu göstermiştir.
Bu çalışmanın katkısı, büyük dil modelleri ile üretilen sentetik verilerin, veri azlığı ve sınıf dengesizliği gibi yaygın NLP problemlerini azaltıcı etkisinin deneysel olarak ortaya konmasıdır. Ayrıca, LSTM tabanlı bir yapay sinir ağı mimarisi ile bu etkinin ölçülmesi, daha ileri düzey modellerle yapılacak kıyaslamalar için bir referans teşkil etmektedir.
Gelecek Çalışmalar
Bu çalışmadan elde edilen sonuçlar doğrultusunda aşağıdaki öneriler geliştirilebilir:
Dikkat mekanizması (attention) veya transformer tabanlı modeller (BERT, RoBERTa vb.) kullanılarak performans karşılaştırmaları yapılabilir.
Duygu yoğunluğu (emotion intensity) ve çok etiketli sınıflandırma (multi-label classification) senaryoları analiz edilebilir.
Türkçe ve çok dilli veri setleriyle benzer deneyler tekrarlanarak dil bağımlılığının etkisi ölçülebilir.
Sentetik veri üretim sürecinde prompt mühendisliği, kontrol edilebilir üretim teknikleri (controlled generation) ve kalite filtreleme üzerine odaklanılabilir.
Sonuç olarak, sentetik verinin yalnızca tamamlayıcı değil, aynı zamanda stratejik bir bileşen olarak doğal dil işleme modellerinde kullanımı, özellikle sınırlı veri içeren alanlarda önemli bir potansiyel sunmaktadır. Gelecekte bu yaklaşımın daha rafine veri üretim süreçleriyle birlikte kullanılması, duygu analizi modellerinin doğruluğunu ve uygulanabilirliğini daha da ileriye taşıyacaktır.
Kaynakça
Alharbi, A., Algarni, A., Aldehim, A., Alohali, M. A., & Alqahtani, F. (2023). Improving emotion detection using data augmentation with GPT-2. International Journal of Advanced Computer Science and Applications, 14(2), 366–372.
Bhagat, P., Killedar, K., & Patil, A. (2021). Sentiment analysis using LSTM. International Journal of Creative Research Thoughts (IJCRT), 9(5), 5323–5330.
Demszky, D., Movshovitz-Attias, D., Ko, J., Cowen, A., Nemade, G., & Ravi, S. (2020). GoEmotions: A dataset of fine-grained emotions. arXiv preprint arXiv:2005.00547.
Maceda, J. C. (2024). Employing synthetic data for addressing the class imbalance in aspect-based sentiment classification. Information Sciences, 672, 119508.
Rani, S., & Kumari, N. (2021). Sentiment analysis using deep learning techniques: A comparative study. International Journal for Research in Applied Science and Engineering Technology, 9(5), 3801–3805.
Xiao, X., Lin, H., & Chen, J. (2019). Improving sentiment classification on imbalanced datasets with transfer learning. Expert Systems with Applications, 130, 15–26.
Zhang, Y., Ren, J., & Zhou, H. (2024). Enhanced sentiment classification in code-mixed texts using hybrid embeddings and synthetic data generation. Expert Systems with Applications, 232, 120126.
Yorumlar